I undertook this evaluation in November 2022 following an interest in cloud data integration services. I hope this provides you with some insights into the capabililities of AWS Glue.
Evaluation
I was looking to understand the capabilities of Glue, and how it could be used to discover, catalog and query data through the Glue feature set which AWS documentation describe as making data preparation simpler, faster, and cheaper. You can discover and connect to over 70 diverse data sources, manage your data in a centralized data catalog, and visually create, run, and monitor ETL pipelines to load data into your data lakes.
Scope of my evaluation
- Ingest data (a simple CSV uploaded to S3)
- Transform the data into parquet format for storage and querying
- Catalog the data and metadata in the Glue catalog across the various schema and file formats for use in analysis using Athena
- Catalog data in each state to have a copy of it at a well-defined phase within a pipeline / process.
AWS Glue
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development[0]
Glue allows you to discover, prepare, integrate and transform your data. Below are the bullet point features of each.
Discover
- Discover and search across all your AWS data sets - The AWS Glue Data Catalog is your persistent metadata store for all your data assets, regardless of where they are located. The Data Catalog contains table definitions, job definitions, schemas, and other control information to help you manage your AWS Glue environment. It automatically computes statistics and registers partitions to make queries against your data efficient and cost-effective. It also maintains a comprehensive schema version history so you can understand how your data has changed over time.
- Automatic schema discovery - AWS Glue crawlers connect to your source or target data store, progresses through a prioritized list of classifiers to determine the schema for your data, and then creates metadata in your AWS Glue Data Catalog. The metadata is stored in tables in your data catalog and used in the authoring process of your ETL jobs. You can run crawlers on a schedule, on-demand, or trigger them based on an event to ensure that your metadata is up-to-date.
- Manage and enforce schemas for data streams - through use of the Schema registry, you can validate and enforce schema
- Automatic scaling based on workload
Prepare
- Dedup and cleanse data
- Edit debug and test ETL code with development endpoints for dev and test cases
- Define, identify and protect sensitive data.
- Create custom transforms
Integrate
- Simplify data integration job development
- Built in job notebooks
- Build complex ETL with job scheduling
- Apply and deploy DevOps best practices
- Read, Update etc data in your data lake
- Deliver high quality data
Transform
- Visual transform of data with drag and drop interface
- Cleansing and transforming streaming data.
Setup
Sign-in to the AWS console, create an IAM policy for Glue and set up your environment to start accessing data.
I used the schools directory from education counts, with the end goal of being able to query for schools by suburb and city, and secondly to query tertiary institutions.
Using the visual builder to query the schools directory CSV I’d placed in an S3 bucket.
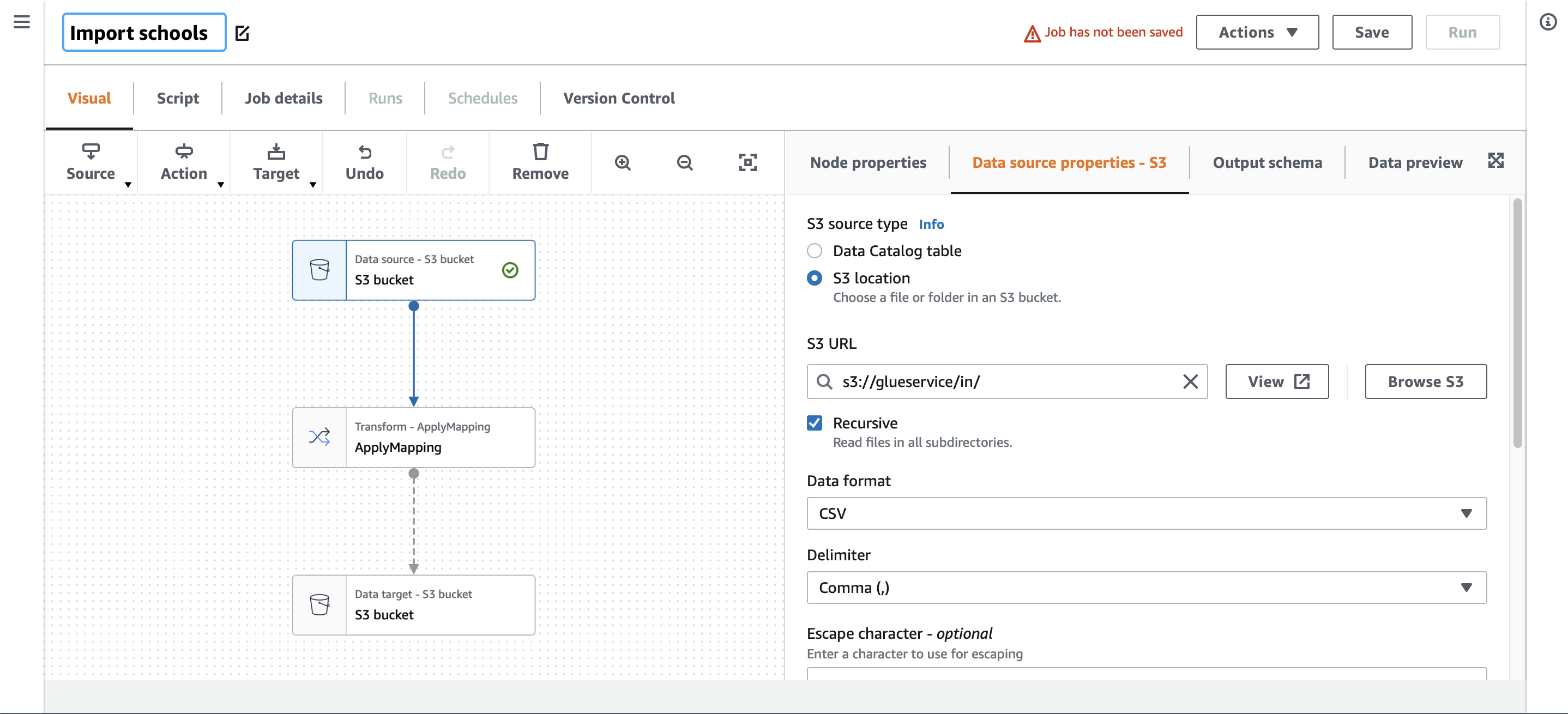
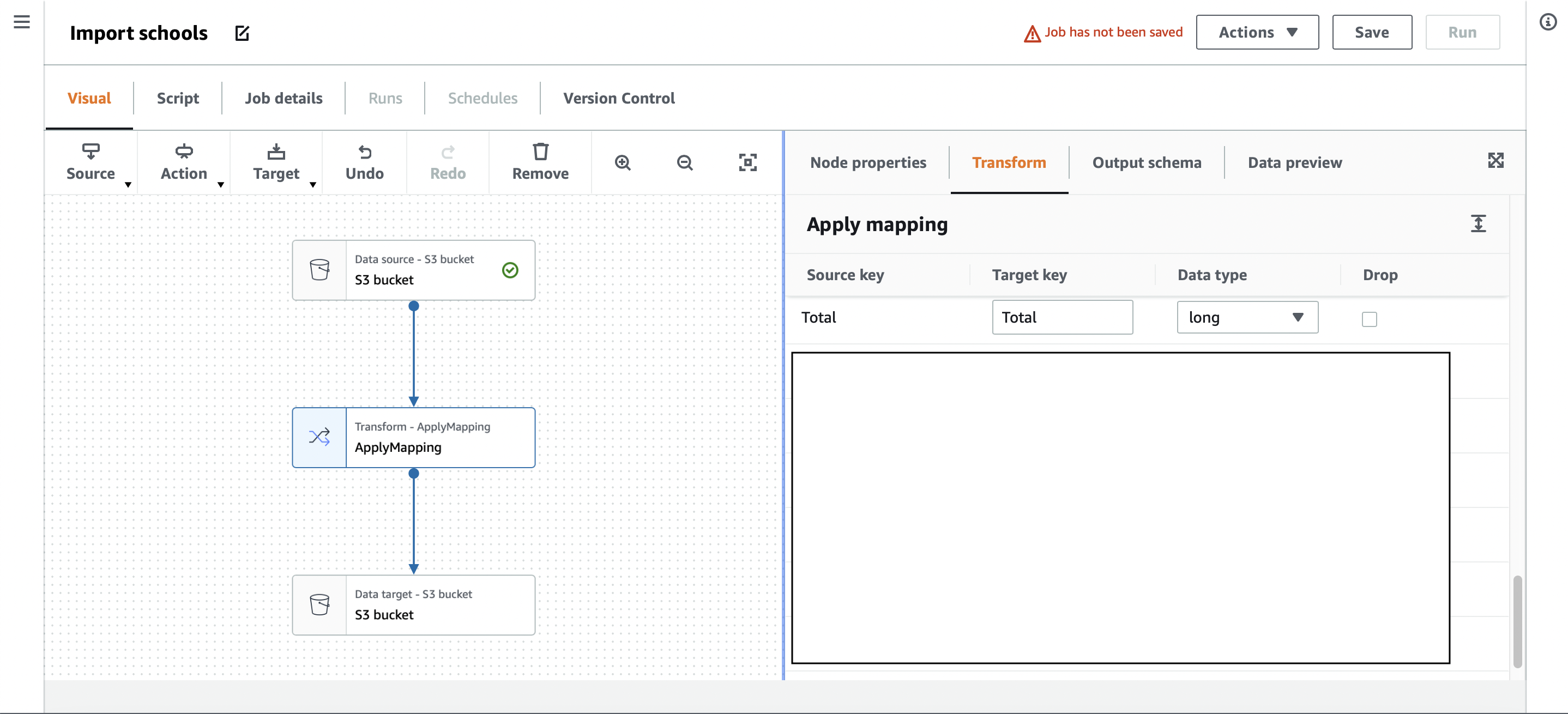
Basic transformation and mapping.
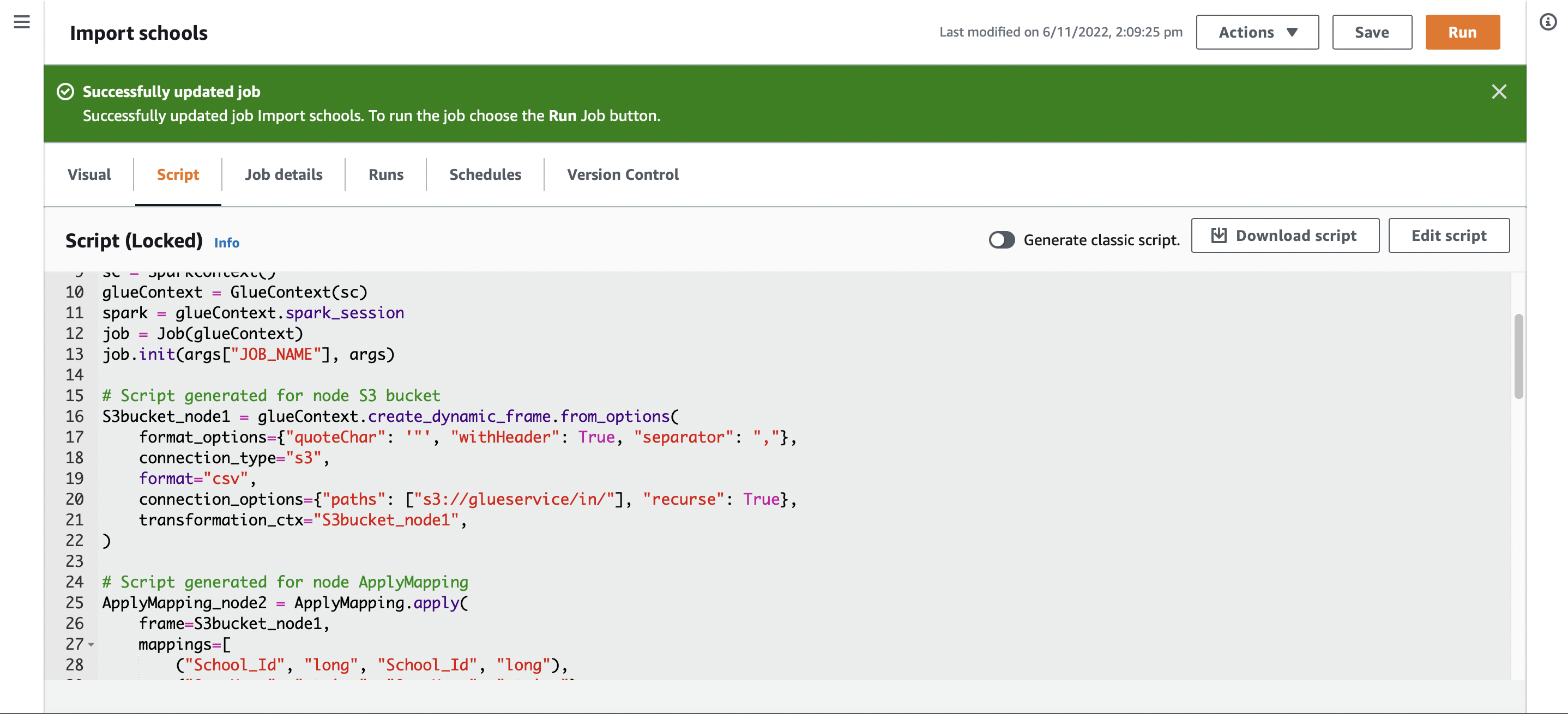
Resulting script from the visual builder, which can be downloaded and extended. Note the use of GlueContext, spark_session etc.
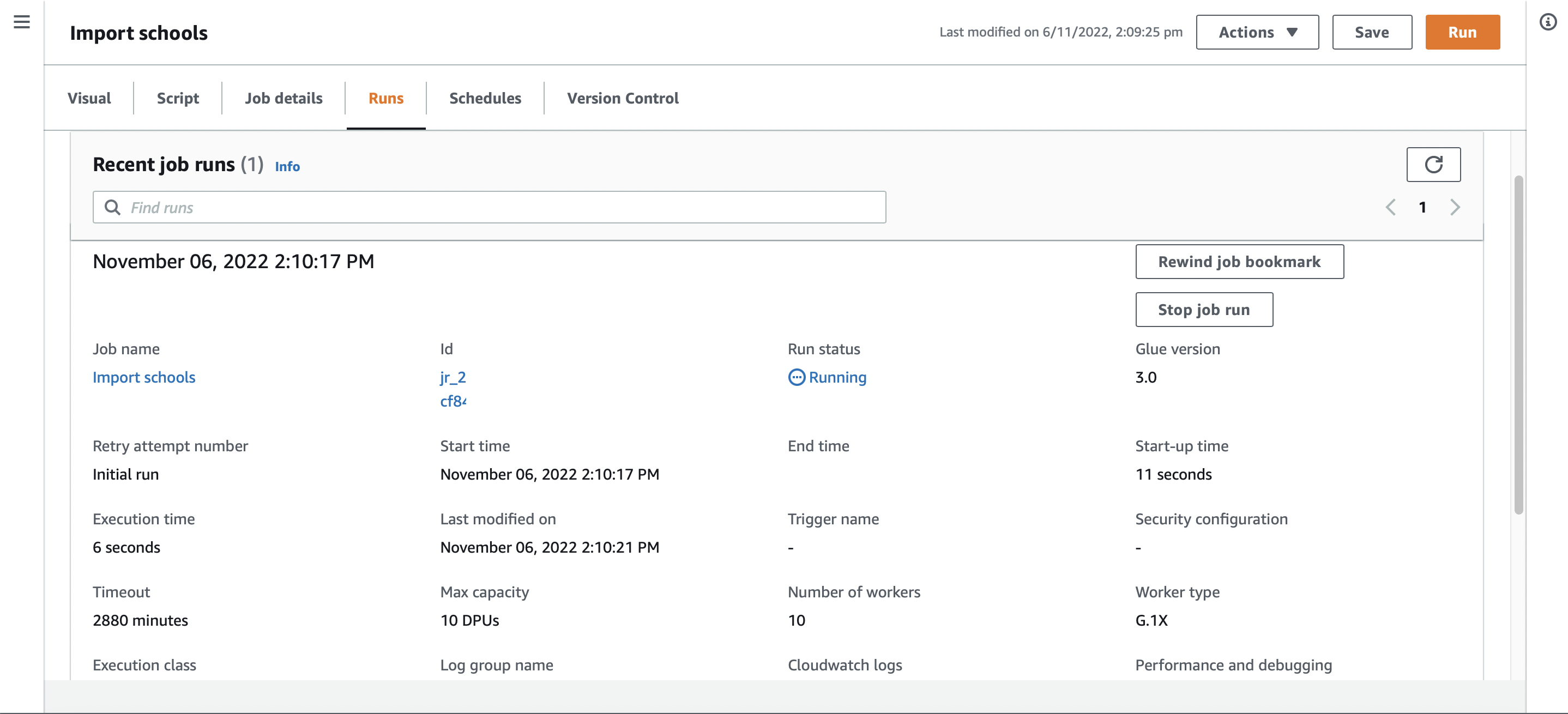
A single job run.
A view of S3, where the job has moved the data from csv to another object, this time in parquet format.
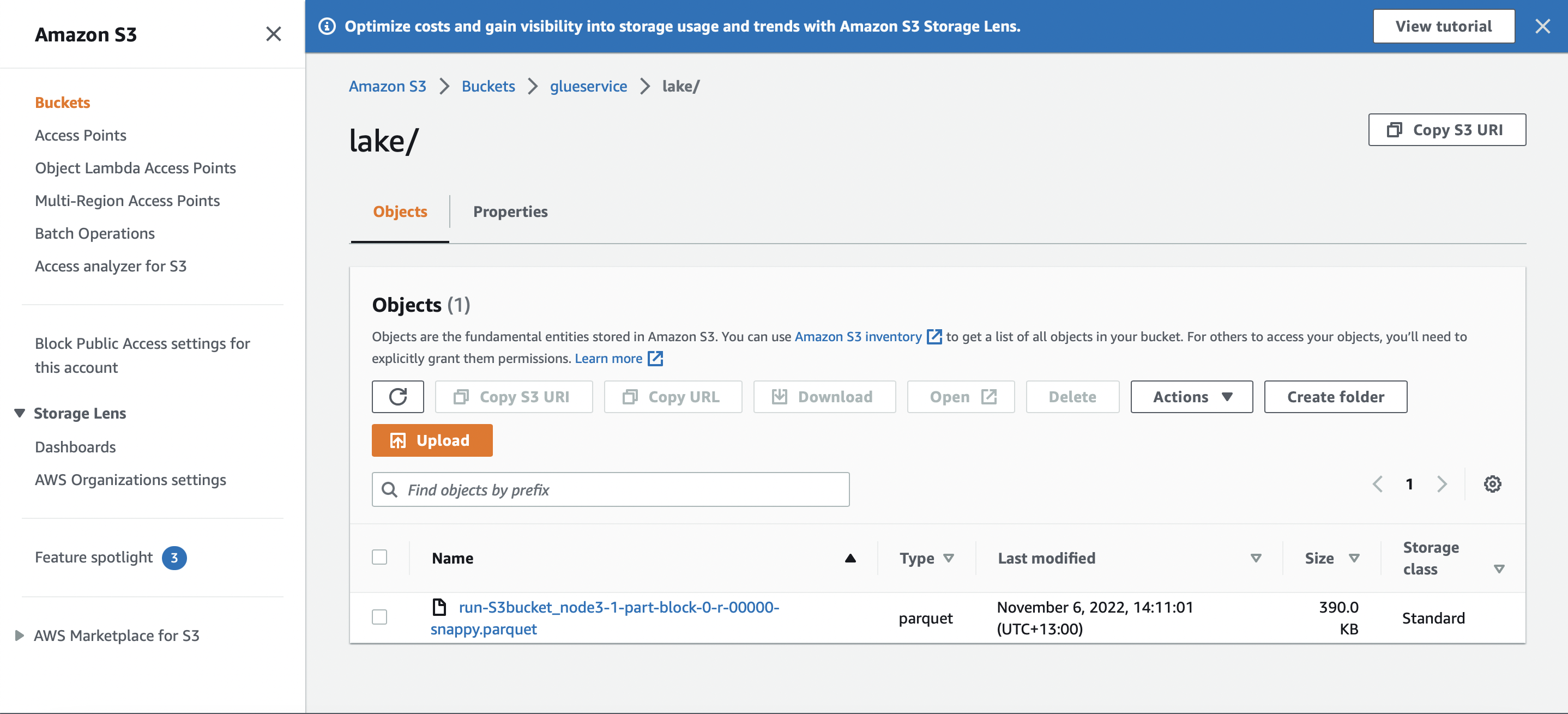
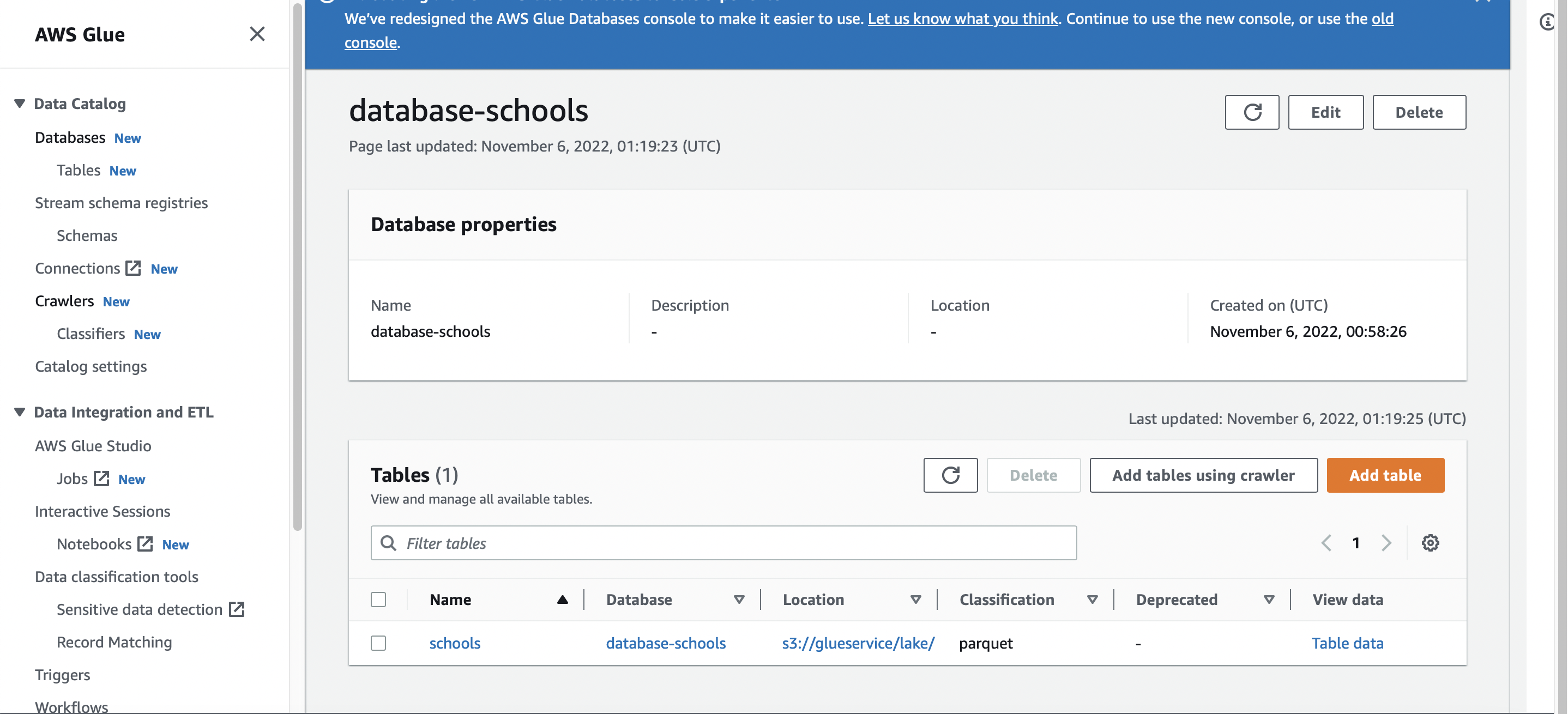
The database in the data catalog showing schools now also in parquet format.
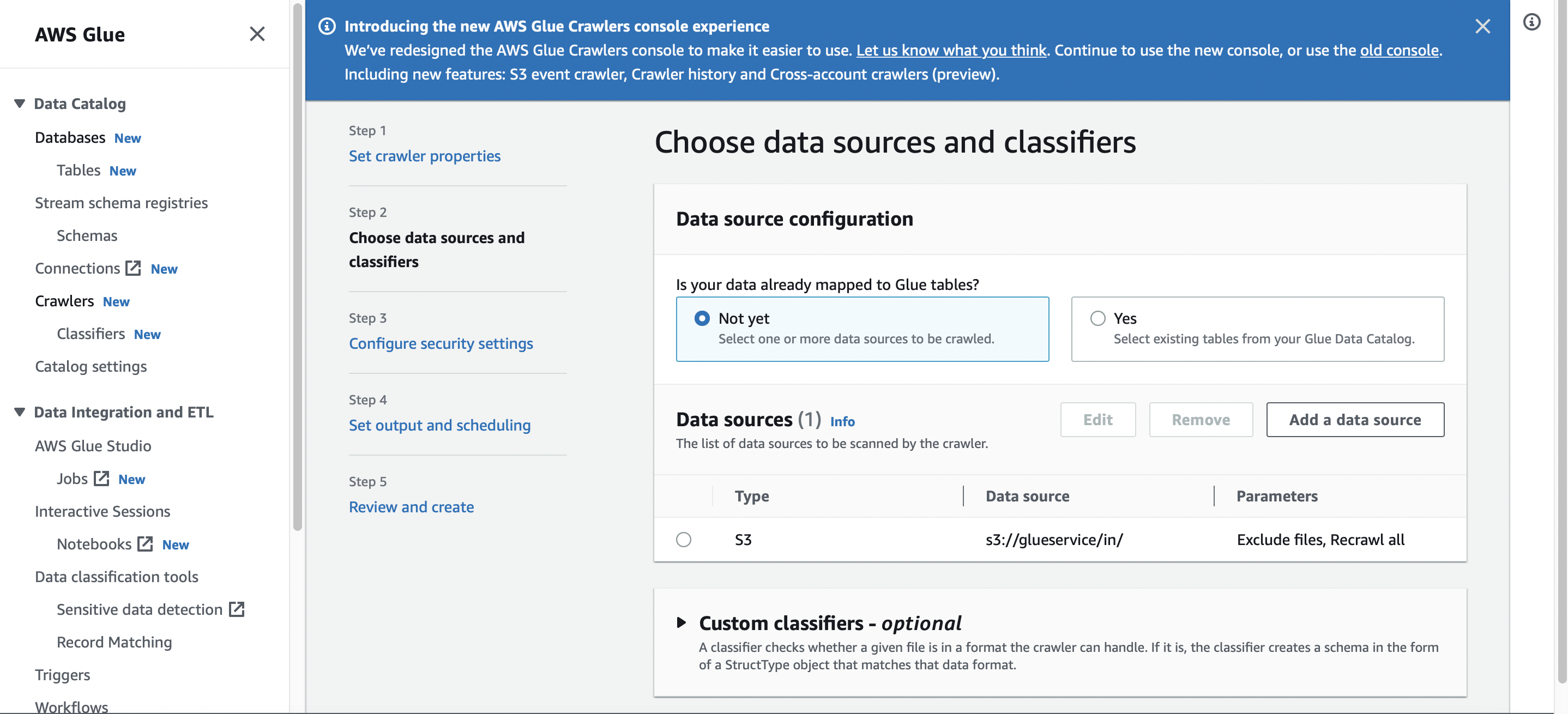
Setting up crawlers and classifiers to pick up new files and new schema
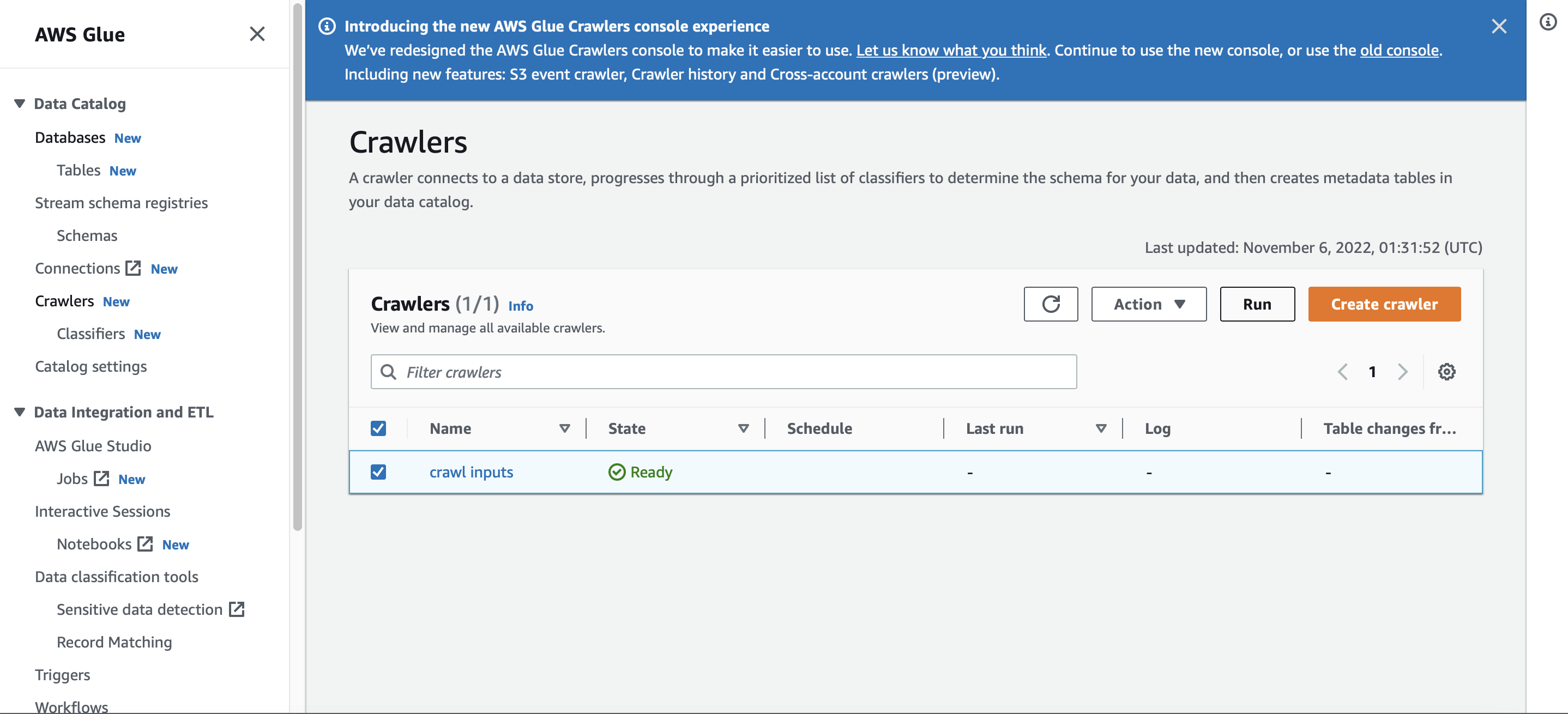
Crawler in ready state
A quick look at the original schools CSV table def, properties and schema is possible
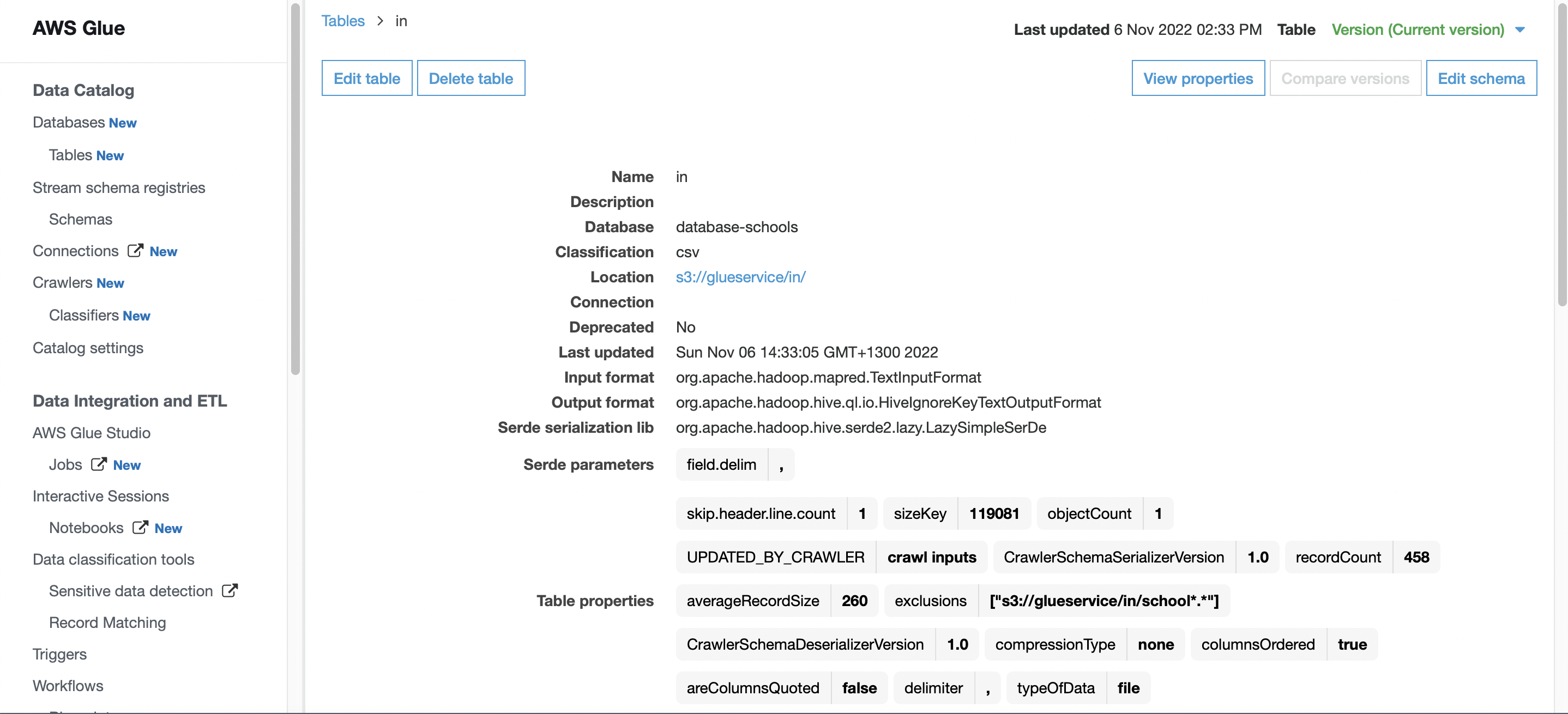
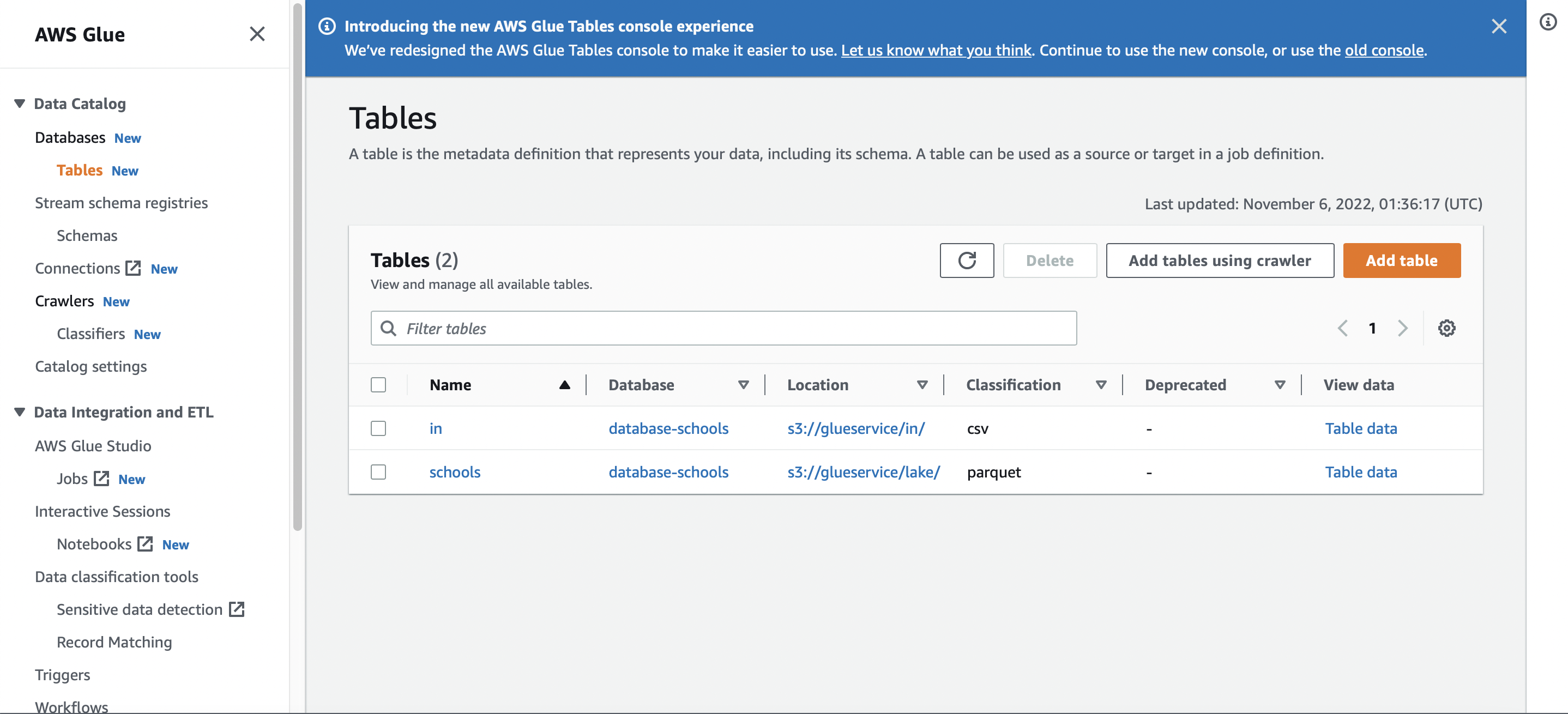
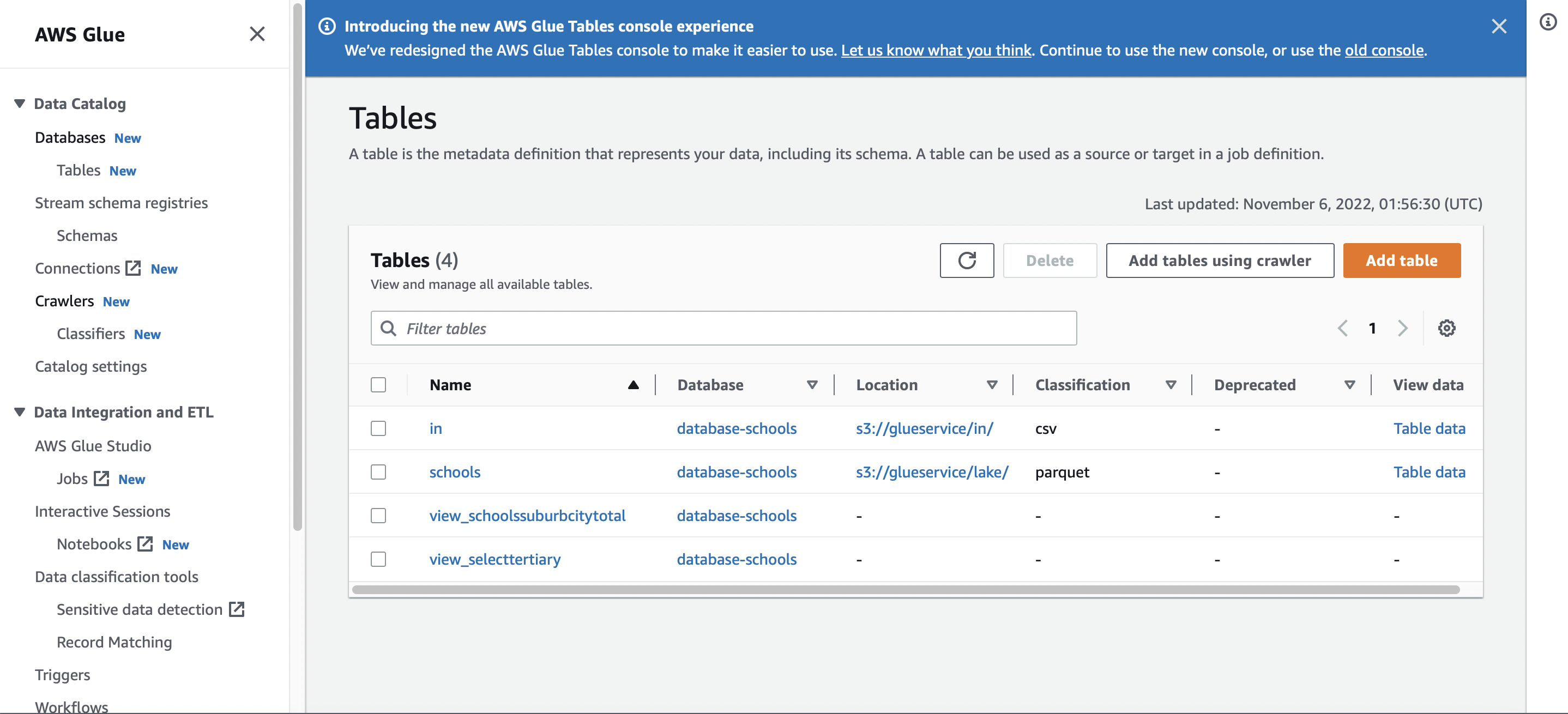
Data Catalog shows all sources and transformed tables (csv and resulting parquet, which aids with data management, transform and analysis)
Analysis and querying is possible with Athena
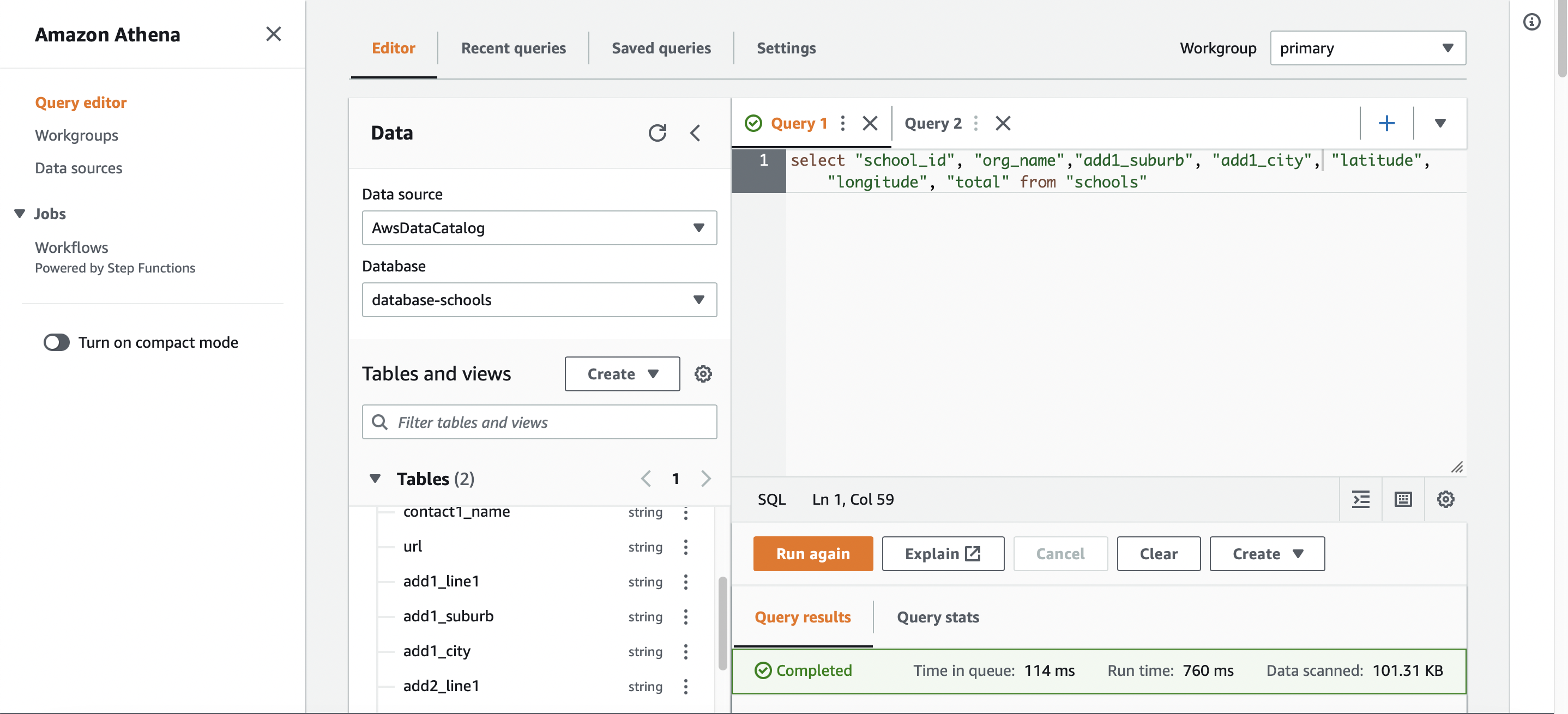
An Athena query against the data catalog, database and table
Using Athena, I created some views which are also available in the catalog now
That’s it in a very short post.
Summary
I found it extremely easy to configure, set up and use Glue. I believe it shows the potential for using Glue for flexible data ingestion, transformation and cataloging, which is then able to be queried using Athena. The flexible transformation to parquet also provides benefits (parquet is a performance-oriented, column-based data format, for an introduction to the format by the standard authority see, Apache Parquet Documentation Overview[1]).
Let me know your thoughts on this post, AWS Glue, any tips and tricks or your thoughts on the service compared to other cloud offerings.
[0] https://aws.amazon.com/glue/
[1] https://parquet.apache.org/docs/overview/

24+ years experience in solving business problems and maximising opportunities through technology in a variety of industries, public and private sector internationally. I founded architectFWD™ to provide knowledge and trusted advice in the areas of strategy, technology, cloud and digital to enable organisations to become Digital Leaders.